서론
앞서 쿠버네티스 Auto Scaling #1 (HPA, VPA)에서 Pod에 대한 Auto Scaling을 다뤘다.
당연한 얘기지만 충분한 Pod를 배치하기 위해선 그에 맞는 Node의 리소스가 받쳐줘야 한다.
그렇다고 확장될 경우를 대비하여 미리 용량이 큰 노드를 준비해놓는다면 리소스 낭비로 이어지기 때문에 적절한 시기에 필요한 만큼 확장/축소시켜 트래픽을 처리하는 것이 바람직하다.
이때 활용할 수 있는 것이 바로 클러스터 오토스케일링 기능이다.
(참고로 EC2 타입별 띄울 수 있는 최대 Pod 개수는 정해져있다. 링크)
클러스터의 오토스케일링을 위한 솔루션에는 크게 Cluster Autoscaler, Karpenter 이외에도 nOps의 Compute Copilot, CAST AI, NeApp Spot Ocean과 같은 제품이 있다.
Amazon EKS는 쿠버네티스의 CA(Cluster Autoscaler)와 Karpenter를 지원한다.
(AWS가 2021년에 Karpenter를 오픈소스로 공개하기 전까지는 CA가 유일한 옵션이었음.)
Cluster AutoScaler(CA)
CA를 설명하기에 앞서 먼저 Pod가 배포되는 과정부터 알아보자.
- 클러스터에 'Pod 만들어주세요' 라고 요청하면 최초 상태는 Pending이 된다.
- 그럼 k8s 스케줄러가 사용 가능한 노드에 대해 일련의 계산을 수행하여 이 노드가 Pod를 가져갈 수 있는지 확인한다.
- 만약 현재 상태로는 Pod를 배치할 수 없다고 판단하면 Pod가 Unschedulable 상태가 된다.
Cluster Autoscaler는 AWS의 Autoscaling Group을 사용한다.
기본적으로 10초마다 Unschedulable pod가 있는지 체크하면서 만약 스케줄링되지 않은 pod가 발견되면 오토 스케일링 그룹을 통해 노드를 추가해서 용량을 증설시키는 방식이다. (참고링크)
kubectl -n kube-system logs -f deployment/cluster-autoscaler
전반적인 흐름은 아래 그림과 같다.

CA 설치(단순 설치는 생략)
Cluster Autoscaler 설치는 AWS Workshop 자료를 참고한다.
동작 테스트
테스트를 위해 deployment의 개수를 10개로 늘려준다.
kubectl scale --replicas=10 deployment/nginx-to-scaleout
CA의 로그를 확인해보면 unschedulable pod를 발견하고 자동으로 auto scaling group의 사이즈를 키우는 것을 확인할 수 있다.


-> 노드가 생성되고 있는 모습

이제 pod의 개수를 원래대로 줄여본다.
kubectl scale --replicas=1 deployment/nginx-to-scaleout
배치할 pod가 없으므로 Scale-in이 진행되고 있다.
다만 Scale-in은 Scale-out과는 다르게 실행 중인 프로세스를 모두 중지시킨 후 서버가 종료되기 때문에 시간이 조금 더 걸린다.
한 마디로 Graceful Shutdown을 위한 시간이라고 볼 수 있음.



추가 옵션
아래는 CA를 설정하면서 몇 가지 고려해볼만한 추가 옵션이다.
CA의 반응 시간을 제어하려면?
어떤 서비스를 올리느냐에 따라 서비스마다 최초 구동 시간이 상이하다.
CA가 Unschedulable pod가 있는지 스캔하는 간격보다 pod가 뜨는 시간이 더 오래 걸린다면 불필요한 스케일링이 발생할 수 있다.
그런 경우를 대비해 pod-scale-up-delay 플래그를 활용할 수 있다.
"cluster-autoscaler.kubernetes.io/pod-scale-up-delay": "600s"
Scale-in의 시간을 조절하려면?
노드의 개수를 축소시키는 시간을 조절할 수 있다.
노드를 더 오래 유지하고 싶을 때(예를 들어 pod가 다시 배치되는 경우)에는 scale-down-unneeded-time 값으로 조절한다.
extraArgs:
scale-down-unneeded-time: 3m
Scale-in을 막으려면?
노드의 annotate로 아래 값을 지정해주면 된다.
"cluster-autoscaler.kubernetes.io/scale-down-disabled": "true"
이렇게
kubectl annotate node <nodename> cluster-autoscaler.kubernetes.io/scale-down-disabled=true
그 외 추가적인 플래그는 아래 공식문서를 참고.
https://aws.github.io/aws-eks-best-practices/cluster-autoscaling/#additional-parameters
Cluster-Autoscaler - EKS Best Practices Guides
Kubernetes Cluster Autoscaler Overview The Kubernetes Cluster Autoscaler is a popular Cluster Autoscaling solution maintained by SIG Autoscaling. It is responsible for ensuring that your cluster has enough nodes to schedule your pods without wasting resour
aws.github.io
Karpenter
Karpenter는 AWS가 개발한 쿠버네티스 노드의 자동 확장 기능을 수행하는 오픈소스 프로젝트이다.
Karpenter의 목표는 클러스터의 용량(capacity) 관리를 단순화하고 현재 워크로드의 요구 사항을 정확하게 충족하는 JIT(Just-In-Time)으로 리소스를 프로비저닝하는 데 있다.
노드의 용량은 크게, 개수는 적게 프로비저닝함으로써 Daemonset 배포 시 혹은 쿠버네티스 시스템 구성 요소들의 오버헤드를 줄이는 이점을 가져갈 수 있다. (통신 오버헤드, etcd 오버헤드, 스케줄링 오버헤드 등등)
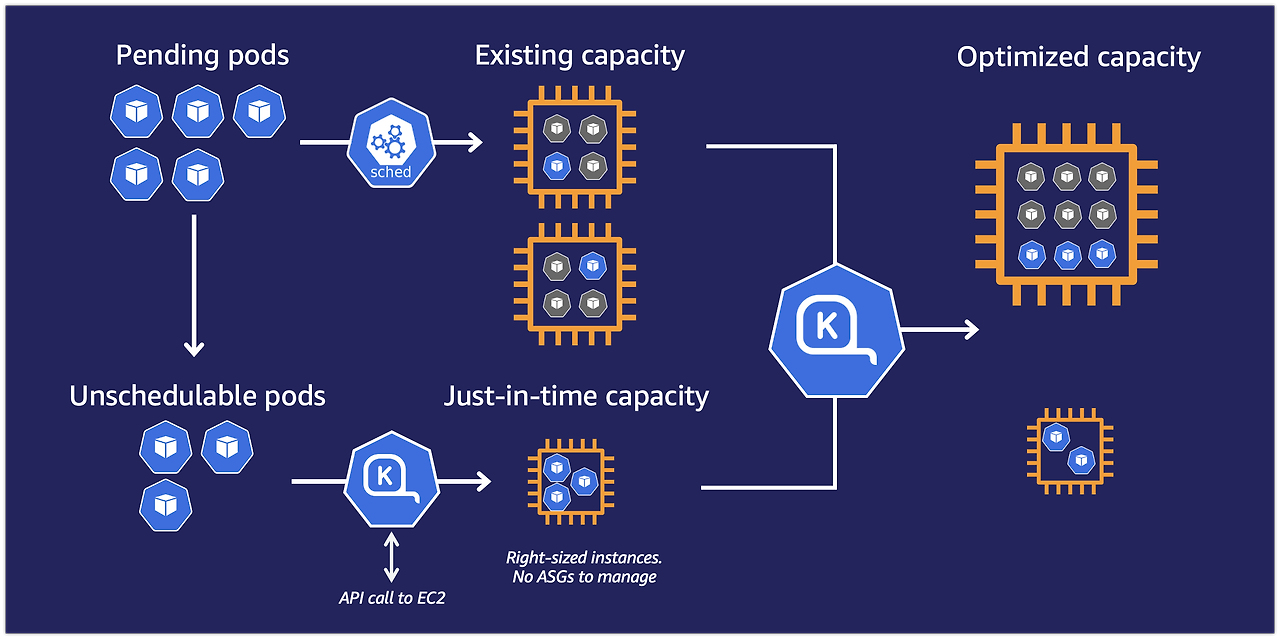
서론에서 얘기했듯 Karpenter는 21년 12월 새로운 쿠버네티스 클러스터 오토스케일러로 발표됐다.
Cluster Autoscaler가 있는데 왜 굳이 또 다른 오토스케일러가 나왔을까?
Cluster Autoscaler를 쓰면서 불편한 점
CA도 오토스케일러로써 충분히 제 역할을 다하고 있다. 오히려 karpenter가 발표되기 전까진 유일한 옵션이었기 때문에 레퍼런스도 그만큼 많다.
다만 사용자가 느끼기에 Karpenter 대비 다소 번거로운 점들이 있다.
1. Auto Scaling Group의 관리
CA는 AWS의 ASG를 활용하고 있다.
예를 들어 클러스터 내 여러 서비스가 있고 각각 다른 타입의 EC2를 사용한다고 가정해보자.
- 테스트 : Spot
- 웹서비스 : M type
- 데이터 분석 : R type
이런 경우 관리자는 각각의 템플릿을 만들고 ASG를 생성해주어야 한다.
뿐만 아니라 변경사항이 생기면 템플릿을 수정하고 버전도 변경해주어야 하기 때문에 대규모 클러스터에서는 이를 관리하기가 굉장히 번거로울 수 있다.
2. 프로비저닝 지연 시간
CA는 ASG를 활용하여 AWS Cloud Provider를 구현한 형태이다.
즉 부하가 발생하면 중간에 AWS 리소스 요청을 한번 거치기 때문에 스케일링 되는데 약간의 지연시간이 발생한다.
아래는 Kubernetes CA FAQ에서 제공하고 있는 Cluster Autoscaler에 대한 SLO 수치이다.
소규모의 경우 30초 이내, 대규모 클러스터의 경우 60초 이내라고 설명한다.

반면 Karpenter는 Kubernetes 스케줄러를 우회하여 EC2 플릿과 직접 상호작용한다.
동작 테스트 부분에서 다시 다루겠지만 Karpenter 컨트롤러는 주기적으로 인스턴스의 가격을 이벤트로 받아오고 필요한 리소스에 맞추어 노드를 직접 프로비저닝 하게 된다.
아마 여기서 속도 차이가 발생하지 않을까 싶다.
Provisioner란?
Karpenter는 provisioner라는 리소스를 활용한다.
CA가 Launch Template에 정의된 값을 참조하여 오토 스케일링을 수행한다면 Karpenter는 이 provisioner에 정의된 값에 따라 노드 오토 스케일링을 수행한다.
말 그대로 서버 스펙, os, 타입, 제약조건과 같은 값을 이 곳에 모두 정의하면 된다.
특징으로는,
- operator 연산자를 통해 여러 다양한 인스턴스 타입을 정의할 수 있다.
Launch Template은 타입을 하나만 설정할 수 있기 때문에 Pod의 요청값에 딱 맞는 노드가 아닐 수 있다.
Karpenter를 사용하면 이러한 bin packing 문제를 개선할 수 있다.
*여기서 bin packing problem이란 n개의 아이템을 m개의 빈에 채워넣는 문제이다.
pod 별로 리소스 요청량이 다르기 때문에 작은 타입의 노드를 여러대 준비해놓는 경우 노드별 유휴 자원이 많이 발생할 수 있다.
그래서 EKS 모범 사례 가이드에서도 볼 수 있듯이 CA를 제대로 쓰려면 노드 그룹 수를 최소화하고 인스턴스 유형을 키우라고 기재돼있다. - 노드 만료에 대한 기본값을 설정할 수 있다.
EKS 클러스터를 운영하다 보면 특정 Node가 오래 사용되어 제때 보안 패치가 안되는 경우가 있다.
이런 경우를 대비하여 노드의 만료기간을 정한다면 주기적인 보안 패치에 대비할 수 있다.
아래는 Provisioner 오브젝트에 대한 예시 yaml 파일이다.
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: default
spec:
labels:
intent: apps
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["spot"]
- key: karpenter.k8s.aws/instance-size
operator: In
values: ["m6i.2xlarge","m6i.4xlarge","c6i.4xlarge"]
limits:
resources:
cpu: 1000
memory: 1000Gi
ttlSecondsAfterEmpty: 30
ttlSecondsUntilExpired: 2592000
providerRef:
name: default
---
apiVersion: karpenter.k8s.aws/v1alpha1
kind: AWSNodeTemplate
metadata:
name: default
spec:
subnetSelector:
alpha.eksctl.io/cluster-name: ${CLUSTER_NAME}
securityGroupSelector:
alpha.eksctl.io/cluster-name: ${CLUSTER_NAME}
tags:
KarpenterProvisionerName: "default"
NodeType: "karpenter-workshop"
IntentLabel: "apps"
Provisioner에서 제공하는 필드에 대해 살펴보자.
Instance Type
리스트 형태로 여러 타입을 설정 가능, 대상을 넓게 정의하는 것이 좋다
- key: node.kubernetes.io/instance-type
- key: karpenter.k8s.aws/instance-family
- key: karpenter.k8s.aws/instance-category
- key: karpenter.k8s.aws/instance-generation
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: default
spec:
requirements:
- key: "karpenter.k8s.aws/instance-family" # 인스턴스 유형
operator: In
values: ["c5", "m5", "r5"]
- key: "karpenter.k8s.aws/instance-cpu" # cpu 크기
operator: In
values: ["4", "8", "16", "32"]
- key: "topology.kubernetes.io/zone" # 가용 영역
operator: In
values: ["ap-northeast-2a", "ap-northeast-2b"]
- key: "kubernetes.io/arch" # cpu 아키텍처
operator: In
values: ["arm64", "amd64"]
- key: "karpenter.sh/capacity-type" # 용량 타입
operator: In
values: ["spot", "on-demand"]
spec.limits.resources
프로비저너가 리소스를 관리할 때 최대 리소스 양을 정해놓는다.
지정된 리밋을 초과하면 기존 노드가 종료될 때까지 새 노드 프로비저닝이 금지된다.
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: default
spec:
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["spot"]
limits:
resources:
cpu: 1000
memory: 1000Gi
nvidia.com/gpu: 2
Weighted Provisioners
.spec.weight 필드를 통해 프로비저너간의 우선순위를 설정할 수 있다.
우선순위가 필요한 경우는 뭐가 있을까?
예를 들어 Savings Plan, 예약 인스턴스를 구입한 경우 얘네들을 먼저 사용해줘야 비용효율적인 운영이 가능하다.
Karpenter에게 default 프로비저너보다 우선하여 reserved-instance 프로비저너를 생성하여 노드 프로비저닝이 가능하다.
이때 사용하는 옵션이 weight 값이다.
Reserved Instance Provisioner
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: reserved-instance
spec:
weight: 50
requirements:
- key: "node.kubernetes.io/instance-type"
operator: In
values: ["c4.large"]
limits:
cpu: 100
Default Provisioner
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: default
spec:
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["spot", "on-demand"]
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
Default Node 설정
pod를 특정 노드에 스케줄링 시키고 싶을 때 Node Selector, Affinity 같은 설정을 한다.
그러나 pod 생성할 때 매번 affinity 설정을 해주면 아래와 같은 제약사항이 발생한다.
1. 일일이 설정하기 번거로움
2. affinity 설정이 변경될 때마다 모든 pod가 재스케줄링 되기 때문에 클러스터 전체에 영향
3. 클러스터 리소스를 상당히 많이 소모함, -> affinity 기능 자체가 상당한 양의 프로세싱을 요구하므로 대규모 클러스터에서는 사용하지 않는 것을 권장한다.(https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/)
리소스를 많이 쓴다는 건? -> 대규모 클러스터에선 스케줄링에 레이턴시가 걸릴 수 있음.
Note:
Inter-pod affinity and anti-affinity require substantial amount of processing which can slow down scheduling in large clusters significantly. We do not recommend using them in clusters larger than several hundred nodes.
Karpenter는 클러스터 전체에 Default 구성을 적용할 수 있다.
Provisioner를 생성할 때 특정 Capacity type, 아키텍처 등을 지정하고 .spec.weight 값을 높게 할당하면 된다.
그 외 별도 요구사항이 있는 경우 나머지 Provisioner를 따라간다.
Default Provisioner
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: default
spec:
weight: 50
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["spot", "on-demand"]
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
ARM64 Provisioner
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: arm64-specific
spec:
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["spot", "on-demand"]
- key: kubernetes.io/arch
operator: In
values: ["arm64"]
- key: node.kubernetes.io/instance-type
operator: In
values: ["a1.large", "a1.xlarge"]
On-demand / Spot 비율
운영을 하다보면 용도별로 온디맨드/스팟을 구분하여 사용할 때가 있다.
Karpenter에서 일정한 비율로 온디맨드와 스팟 인스턴스를 분할하는 방법을 살펴보자.
먼저 스팟과 온디맨드 각각의 프로비저너를 생성한다.
capacity-spread 라는 새 레이블을 만들고 서로 겹치지 않는 값을 할당한다.
아래 예시는 스팟에 4개, 온디맨드에 1개
-> 스팟:온디맨드 노드 비율이 4:1이 됨
Spot Provisioner
requirements:
- key: "karpenter.sh/capacity-type"
operator: In
values: [ "spot"]
- key: capacity-spread
operator: In
values:
- "2"
- "3"
- "4"
- "5"
On-Demand Provisioner
requirements:
- key: "karpenter.sh/capacity-type"
operator: In
values: [ "on-demand"]
- key: capacity-spread
operator: In
values:
- "1"
여기에 위에서 설정한 capacity-spread 레이블을 토폴로지 키로 topologySpreadConstraints를 활용해 분산되게 배포한다.
Topology Spread Constraint
topologySpreadConstraints:
- maxSkew: 1
topologyKey: capacity-spread
whenUnsatisfiable: DoNotSchedule
여기서 잠시 토폴로지 분배 제약조건(Topology Spread Constraint)에 대해 알아보자.
Topology Spread Constraint
Pod를 분배하는 방법은 크게 Node 기준에서의 NodeAffinity와 Pod 기준에서의 PodAffinity가 있다.
Topology Spread Constraint는 Pod가 클러스터 내에서 물리적 혹은 논리적 위치에 균등하게 배포되도록 하는 기능이다.
개념만으론 와닿지 않으니 아래 예시를 살펴보자.
AWS의 서울 리전(ap-northeast-2) 기준으로 ap-northeast-2a, ap-northeast-2c 라는 가용영역에 각 노드가 한 대씩 있다고 가정해보자.
여기서 이 가용영역이 토폴로지 도메인(Topology Domains)이 된다.
토폴로지 도메인은 pod가 분포될 수 있는 물리적 혹은 논리적 영역을 뜻한다 (노드, 데이터센터 등등)
노드에 라벨을 붙여서 pod가 균등하게 배포되는지 확인해보자
- topology.kubernetes.io/region=ap-northeast-2 (공통)
- topology.kubernetes.io/zone=ap-northeast-2a (a 가용영역의 노드에)
- topology.kubernetes.io/zone=ap-northeast-2c (c 가용영역의 노드에)
- 노드 명은 kubectl get nodes를 입력했을 때 나오는 NAME 필드의 값이다.
kubectl lable node <A az 노드 명> topology.kubernetes.io/region=ap-northeast-2 topology.kubernetes.io/zone=ap-northeast-2a
kubectl lable node <C az 노드 명> topology.kubernetes.io/region=ap-northeast-2 topology.kubernetes.io/zone=ap-northeast-2c
라벨을 지정한 후에는 아래 명령어를 통해 노드에 설정된 라벨을 확인할 수 있다.
kubectl get nodes -o jsonpath="{.items[*].metadata.labels}" | jq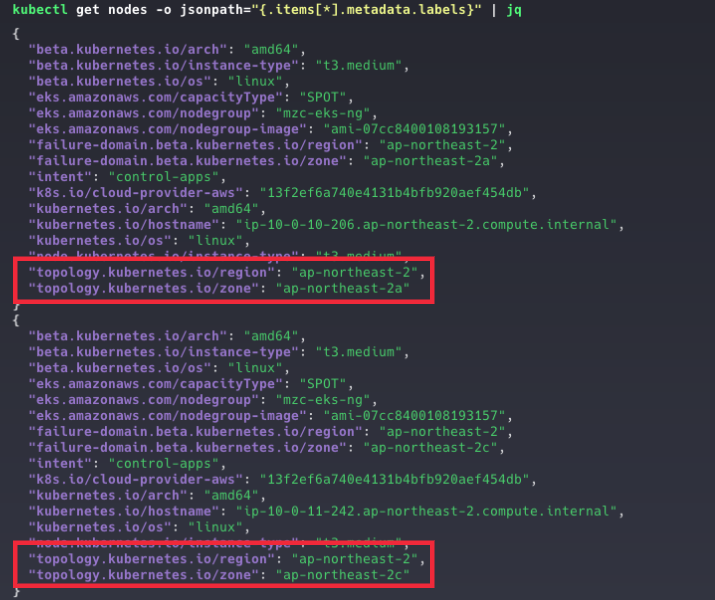
아래 yaml 파일을 통해 10개의 pod를 생성해보자.
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-spread
namespace: karpenter
spec:
replicas: 10
selector:
matchLabels:
app: deploy-spread
template:
metadata:
labels:
app: deploy-spread
spec:
containers:
- image: nginx
name: nginx
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: deploy-spread
여기서 topologySpreadConstraints 부분에 어떤 설정값들이 있는지 살펴보자
- maxSkew (Required)
파드가 균등하지 않게 분산될 수 있는 정도를 나타낸다.
만약 1로 설정했다면 최대 1개의 pod까지 뷸균형을 허용한다는 뜻이다.
(e.g. 5개의 pod를 띄운다면 a존에 2개, c존에 3개까지는 허용, a존 4개 c존 1개는 불가) - topologyKey
노드 라벨의 Key 값 - whenUnsatisfiable
분산 제약 조건을 만족하지 않을 경우 Pod를 어떻게 처리할지에 대한 방법이다.- DoNotSchedule : 기본값이며 쿠버네티스 스케줄러에 스케줄링을 하지 말라고 알려줌
- ScheduleAnyway : 쿠버네티스 스케줄러에 skew를 최소화하는 노드에 높은 우선순위를 부여하면서 스케줄링을 계속 하도록 지시
- labelSelector
일치하는 pod를 찾기 위해 사용(토폴로지 도메인에 속할 파드를 결정짓기 위함)
Pod가 배포된 노드를 확인해보면 a존과 c존에 각각 5개의 pod가 배포된 것을 확인할 수 있다

운이 좋게 5개씩 배포가 됐을 수 있지만 운영을 하다보면 모든 노드의 부하 비율이 동일한 것을 보장할 수 없다.
제약조건을 없앤 후 배포해보면 5:5로 배포되지 않는 것을 알 수 있다.

간단하게 Cluster AutoScaler와 Karpenter에 대해 살펴보았다.
처음부터 CA를 사용하여 대규모 클러스터를 운영했다면 Karpenter로 넘어가는 게 쉽지 않을 것 같은데
이제 막 EKS 도입을 고려하는 중이라면 Karpenter를 안쓸 이유가 없어보인다.
'Kubernetes' 카테고리의 다른 글
| 쿠버네티스 Auto Scaling #1 (HPA, VPA) (0) | 2023.11.20 |
|---|---|
| kubernetes에 metrics-server 설치하기 (0) | 2022.10.06 |
| Helm 인강 정리 (0) | 2021.10.08 |
| Helm Chart를 이용하여 nginx 설치하기 (0) | 2021.10.08 |
| Helm이란? (0) | 2021.10.01 |